

Producing and processing real-time data are two sides of a coin. Imagine you run a company that continuously generates a steady stream of data that needs to be processed efficiently. Traditional solutions for handling this data using Kafka's producer and consumer APIs can be bulky because of the lines of code you'd need to write, making it challenging to implement and maintain.
Well, there's a solution to this called
In this article, you'll get a basic understanding of how real-time stream processing works by dissecting Kafka streams. You'll get an in-depth explanation of stream processing apps, some basic operations in Kafka streams, and the processor API. By the end of this article, you'll have a holistic overview of how real-time streaming works while using Kafka streams.
What are Kafka streams?
Kafka Streams is a Java library that you use to write your stream processing applications just like you would for any other application. It's a standalone app that streams records to and from Kafka.
This means it's something that you'd run on its server rather than on the same broker as your Kafka cluster. Kafka streams are an unrelated process that connects to the broker over the network and can be run anywhere that can connect to the broker.
What is a Kafka streams application?
Basically, these are software programs that continuously ingest, process, and analyze data in real time as it is produced. These applications are designed to handle continuous real-time data streams, and Kafka Streams is a client library you can use to build them.
You can create a Kafka streaming application of any kind. Some examples of such apps are data transformation, enrichment, fraud detection, monitoring and alerting, etc.
Benefits of using Kafka streams
Aside from writing less code for real-time data processing, there are more benefits to using Apache Kafka streams. Below are some of these benefits:
-
No need for separate clusters: As a Java library, Kafka Streams applications run independently and connect to Kafka brokers over the network. Therefore, unlike stream processing frameworks like Spark Streaming or Apache Flink, they don't require setting up and managing a separate cluster. This simplifies deployment and reduces operational overhead.
-
Highly scalable and fault-tolerant: Kafka Streams inherit Kafka's scalability and fault-tolerance characteristics. It can quickly scale out by adding more instances to handle increased data volumes. Additionally, Apache Kafka Streams applications can automatically recover from failures, ensuring continuous data processing without loss or duplication.
-
Exactly-once processing: Kafka Streams offers exactly-once semantics, ensuring every record is processed precisely once. This capability is tightly integrated with
Kafka's transaction features , providing high data accuracy and reliability. This is crucial for applications that require precise data processing, such as financial transactions or inventory management systems. -
One record at a time processing: Kafka Streams processes each record individually, avoiding the need for batching. Unlike batch processing frameworks, this real-time processing model allows immediate response to incoming data, reducing latency by handling data in chunks. This is particularly beneficial for applications that require low-latency processing, such as real-time monitoring systems.
-
Highly flexible: Apache Kafka Streams is designed to handle applications of any size, from small-scale to large-scale production systems. The same codebase can scale seamlessly with the application's growth, making it an ideal choice for projects that may start small but have the potential to expand significantly.
How does a Kafka streams app work?
The core of a Kafka stream application is its topology, which defines how data flows through various processing nodes. A topology is a directed graph of stream processors (nodes) and streams (edges).
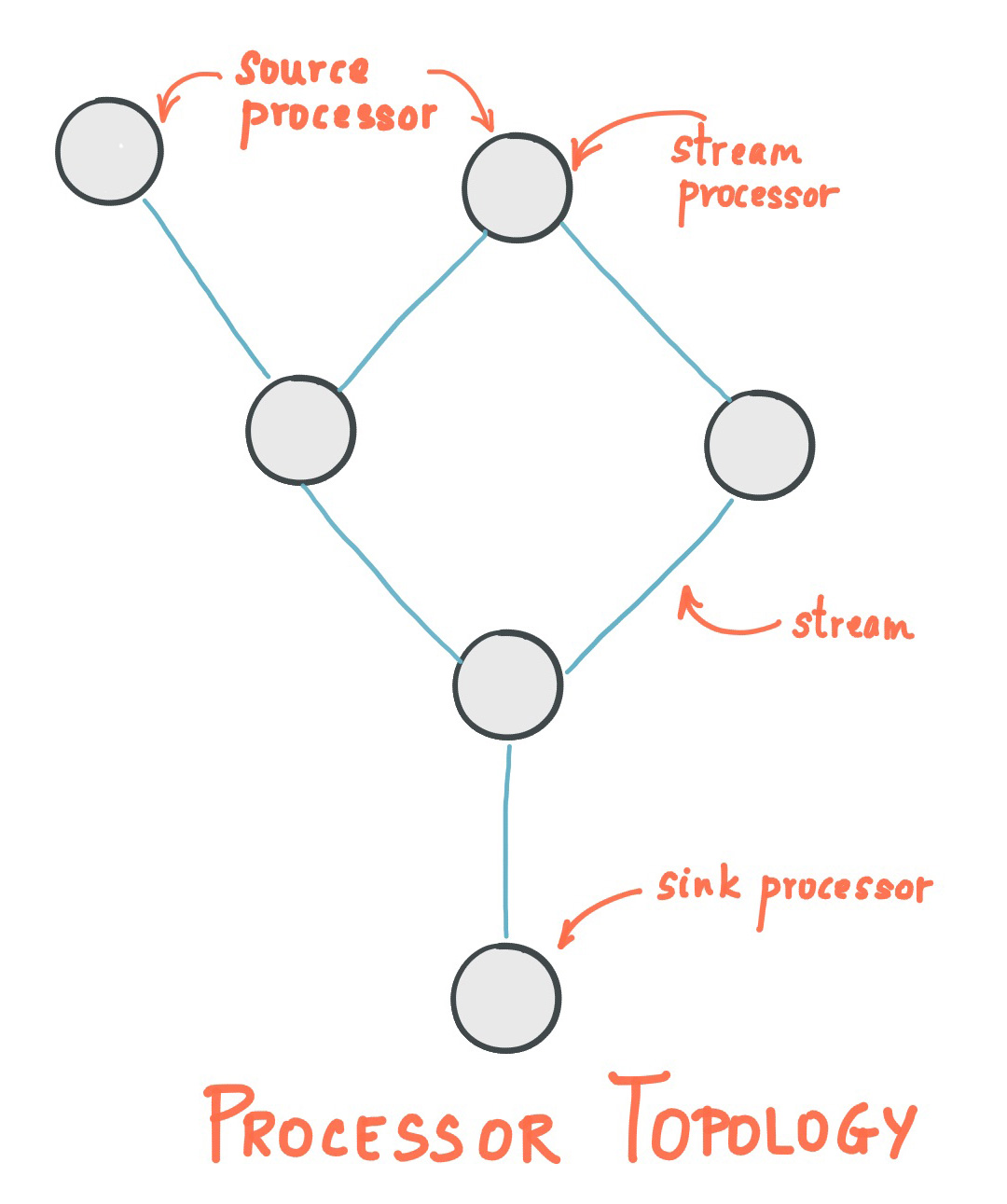
Each node in the topology represents a processing step, such as filtering, transforming, or aggregating data.
*
-
Source Processor: Reads data from a Kafka topic.
-
Stream Processor: Applies operations on the incoming data stream (e.g., map, filter, join).
-
Sink Processor: Writes the processed data to a Kafka topic.
A Kafka Streams application works by acting both as a producer and a consumer. It begins by consuming messages from a source, such as a Kafka topic. For example, if there is a topic named "clicks" that contains user clickstream data, the application reads these messages as they come in.
Once the messages are consumed, the application processes them through a series of transformations defined in a topology of stream processors.
These transformations can include filtering the messages to retain only those that contain specific events, such as user clicks. The application evaluates each message against the filter criteria, ensuring only relevant data is processed further.
After filtering, the application can transform or map the messages into different formats or aggregate them as needed. For instance, it might map the raw click data into a more user-friendly format or count the number of clicks per user.
This often involves stateful operations, where the application maintains a local state stored in state stores. These state changes are logged to changelog topics, providing fault tolerance and allowing the state to be reconstructed in case of failure.
Finally, the processed messages are produced to an output Kafka topic. Continuing with the example, after aggregating click counts per user, the application writes these counts to a topic named "aggregated clicks."
Throughout this process, Kafka’s built-in fault tolerance mechanisms ensure the application can gracefully handle failures. Additionally, the application can scale by adding more instances, automatically rebalancing the load across available resources, and maintaining efficient processing.
Basic operations in Kafka streams
Kafka streams offer two primary ways to define stream processing topologies: Kafka Streams DSL (Domain Specific Language) and the Processor API.
The DSL provides high-level abstractions and common data transformation operations, such as map, filter, join, and aggregation, making it easy to build stream processing applications.
This section will focus on the basic operations available in the Kafka Streams DSL, demonstrating how to transform, filter, join, and aggregate data streams with code examples to illustrate each operation.
Mapping Operations
Mapping operations in Kafka Streams are used to transform data within the stream. There are two primary mapping operators: mapValues and map.
mapValues
This operator transforms the value part of the key-value pair without changing the key. It is useful when the key remains constant and only the value needs modification.
For example, to remove the first five characters of a credit card transaction string, you can use mapValues:
KStream<String, String> maskedTransactions = transactions.mapValues(value ->
value.substring(5)
);
map
This operator transforms both the key and the value of the record, allowing for the redefinition of key-value pairs.
For instance, to categorize data by different criteria, you might redefine both the key and the value:
KStream<String, String> categorizedData = transactions.map((key, value) ->
new KeyValue<>(newKeyBasedOnValue(value), value)
);
NOTE: Using map to change the key can lead to repartitioning, which might impact performance. Hence, mapValues is preferred unless altering the key is necessary.
Filtering Operations
Filtering operations enable selective processing of records based on specific criteria. The filter operator creates a new stream containing only records that meet the defined predicate.
For example, to retain only records with values greater than 1,000:
KStream<String, String> filteredTransactions = transactions.filter(
(key, value) -> Integer.parseInt(value) > 1000
);
Avoid directly modifying the key or value when using the filter operator. Filtering should be seen as generating a new event stream based on existing data.
Join Operations
Join operations combine records from two streams or a stream and a table based on their keys. Joins can be categorized into stream-stream joins and stream-table joins.
Stream-Stream Join
This joins two KStreams based on their keys, allowing for windowed joins over a specified time interval.
For example, to join a stream of user clicks with a stream of user purchases:
KStream<String, ClickEvent> clicks = builder.stream("clicks");
KStream<String, PurchaseEvent> purchases = builder.stream("purchases");
KStream<String, CombinedEvent> joinedStream = clicks.join(
purchases,
(click, purchase) -> new CombinedEvent(click, purchase),
JoinWindows.of(Duration.ofMinutes(5))
);
Stream-Table Join
This joins a KStream with a KTable, enriching the stream with additional information from the table.
For example, to enrich a stream of orders with customer details from a table:
KStream<String, Order> orders = builder.stream("orders");
KTable<String, Customer> customers = builder.table("customers");
KStream<String, EnrichedOrder> enrichedOrders = orders.join(
customers,
(order, customer) -> new EnrichedOrder(order, customer)
);
Aggregation Operations
Aggregation operations in Kafka Streams combine multiple records into a single record, commonly used for computing summaries or statistics over a window of time.
Count
Aggregates records by counting the number of records per key. For example, to count the number of transactions per user:
KTable<String, Long> transactionCounts = transactions
.groupByKey()
.count(Materialized.as("transaction-counts-store"));
Reduce
Combines records using a reduction function. For example, to sum transaction amounts per user:
KTable<String, Integer> transactionSums = transactions
.groupByKey()
.reduce(
(aggValue, newValue) -> aggValue + Integer.parseInt(newValue),
Materialized.as("transaction-sums-store")
);
Aggregate
Allows for more complex aggregations by specifying an initializer and an aggregator.
For example, to calculate the average transaction amount per user:
KTable<String, Double> averageTransactionAmounts = transactions
.groupByKey()
.aggregate(
() -> 0.0,
(key, newValue, aggValue) -> (aggValue + Integer.parseInt(newValue)) / 2,
Materialized.as("average-transaction-amounts-store")
);
Processor API
The Processor API in Kafka Streams is a low-level API that allows developers to define and connect custom processors for more granular control over stream processing.
Unlike the high-level DSL (Domain Specific Language), which provides predefined operations, the Processor API offers the flexibility to implement custom processing logic.
A Kafka Streams application using the Processor API starts by defining a topology, but instead of using built-in operations, it uses custom processors.
Each processor node in this topology can perform any desired operation on the incoming messages. For instance, a processor can read messages from a source topic, apply custom transformations, and then forward the processed messages to downstream processors or sink topics.
Custom processors are implemented by extending the AbstractProcessor class and overriding the process method. This method contains the logic for processing each record. The application can also use Punctuator for scheduled periodic actions, like aggregating data regularly.
State stores can be accessed within processors to maintain and update the state, supporting stateful operations. These state changes are logged to changelog topics to ensure fault tolerance.
Once the processors are defined, they are connected using aTopologyBuilder, specifying the source, custom, and sink processors.
This topology is then passed to the Kafka Streams application for execution. The application starts by consuming messages from the specified source topics, passing them through the custom processors for processing, and writing the processed messages to the sink topics.
KStreams and KTables
These components provide the fundamental building blocks for stream processing, which enables you to define, process, and manage data streams effectively.
KStreams
KStreams are used for processing continuous, real-time streams of data where each record is an immutable fact or event. You use KStreams when you need to process events as they happen, perform transformations, and react to each incoming piece of data individually.
For instance, in an application that processes user clickstream data, KStreams allow you to filter clicks, map user actions, and transform data in real-time. This is crucial for scenarios where the immediate processing of each event is required, such as detecting fraud, updating user sessions, or performing real-time analytics.
Key use cases for KStreams
Some real-time use cases of KStreams include:
- Event-Driven Architectures: Process and react to events as they occur.
- Real-Time Analytics: Perform computations on the fly for live dashboards.
- Stateless Transformations: Apply transformations where state between records is not maintained, such as filtering or mapping.
KTables
KTables, on the other hand, are necessary for managing stateful data where the latest state of each key is important. A KTable represents a changelog stream of updates, maintaining the current state for each key, making it ideal for scenarios where you need to aggregate, join, or query the latest state of the data.
For example, in a customer management system, a KTable can keep track of the latest customer profile information, updating the state as new information arrives. This is crucial for applications requiring querying the current state, such as maintaining counts, computing averages, or joining other data streams.
Key use cases for KTables
Some real-time use cases of KTables include:
- Stateful Aggregations: Compute and maintain the current state, such as counts, sums, or averages.
- Table Operations: Perform operations like joins and lookups where the current state is needed.
- Materialized Views: Create views of the latest state of data for querying and further processing.
When to use KStreams and KTables
You should use KStreams when:
- You need to process each event as it happens.
- The processing involves stateless transformations or operations.
- The application requires real-time reaction to events.
You should use KTables when:
- You need to maintain and query the latest state of data.
- The processing involves stateful operations like aggregations or joins.
- The application requires access to the current state of the data.
Conclusion
This article reveals how much you can do with Kafka streams. We broke down what Kafka streams are, how they work, and their benefits. We reviewed the basic operations in Kafka streams, Processor API, and KTables & KStreams.
By relying on Kafka streams, you can build robust and scalable stream processing applications that meet the demands of modern data-driven environments.