

Authors:
(1) Shengqiong Wu, NExT++, School of Computing, National University of Singapore;
(2) Hao Fei ,from NExT++, School of Computing at the National University of Singapore, serves as the corresponding author: haofei37@nus.edu.sg.
(3) Leigang Qu, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: haofei37@nus.edu.sg;;
(4) Wei Ji, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: haofei37@nus.edu.sg;;
(5) Tat-Seng Chua, Hao Fei, NExT++, School of Computing, National University of Singapore is the corresponding author: haofei37@nus.edu.sg;.
Table of Links
- Abstract and 1. Introduction
- 2 Related Work
3 Overall Architecture
4 Lightweight Multimodal Alignment Learning - 5 Modality-switching Instruction Tuning
- 5.1 Instruction Tuning
- 5.2 Instruction Dataset
- 6 Experiments
- 6.1 Any-to-any Multimodal Generation and 6.2 Example Demonstrations
- 7 Conclusion and References
5 Modality-switching Instruction Tuning
5.1 Instruction Tuning
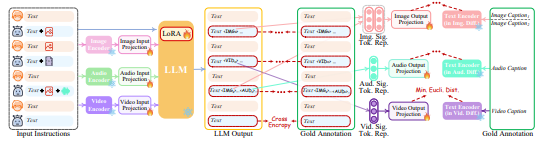
Despite aligning both the encoding and decoding ends with LLM, there remains a gap towards the goal of enabling the overall system to faithfully follow and understand users’ instructions and generate desired multimodal outputs. To address this, further instruction tuning (IT) [97, 77, 52] is deemed necessary to enhance the capabilities and controllability of LLM. IT involves additional training of overall MM-LLMs using ‘(INPUT, OUTPUT)’ pairs, where ‘INPUT’ represents the user’s instruction, and ‘OUTPUT’ signifies the desired model output that conforms to the given instruction. Technically, we leverage LoRA [32] to enable a small subset of parameters within NExT-GPT to be updated concurrently with two layers of projection during the IT phase. As illustrated in Figure 4, when an IT dialogue sample is fed into the system, the LLM reconstructs and generates the textual content of input (and represents the multimodal content with the multimodal signal tokens). The optimization is imposed based on gold annotations and LLM’s outputs. In addition to the LLM tuning, we also fine-tune the decoding end of NExT-GPT. We align the modal signal token representation encoded by the output projection with the gold multimodal caption representation encoded by the diffusion condition encoder. Thereby, the comprehensive tuning process brings closer to the goal of faithful and effective interaction with users.
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.